Для одного из своих приложений мне понадобилось достаточно много информации которой полно на различных wiki но всё это собирать вручную достаточно геморно. По этому я решил вооружится C# и распарсить всё что мне надо. Мы будем использовать хорошую библиотеку Html Agility Pack которая берёт на себя большую часть работы и предоставляет для нас удобное DOM дерево с которым мы можем работать. Она поддерживает XPath запросы, LINQ и много всего вкусного.

Так, прежде чем приступить к парсингу проведём пару подготовительных операций. Для начала переменные :
Начинаем работу.
Вам понадобиться знание HTML и желательно опыт работы с XML, иначе вы вряд-ли сможете понять в полной мере описанное ниже. Для начала нам нужно скачать библиотеку и подключить её к проекту, для этого берём из архива папку под нужный нам фреймворк я взял Net40 и ложем её в наш проект (перетягиваем в окошко обозреватель решения). Далее кликаем правой кнопкой мыши на Reference всё в том же обозревателе решений и нажимаем добавить ссылку. Там на вкладке обзор нужно выбрать нашу библиотеку
Работаем собственно
В качестве подопытного у нас выступит сайт dota2.ru и мы попробуем получить ссылки на страницы всех героев для последующей их обработки. Обработка самих страниц с героями не сильно отличается от обработки страницы с их каталогом. Сперва нам нужно определится с структурой страницы. К слову с этим сайтом всё достаточно просто, так-как структура хорошо продуманна и все элементы имеют свою названия, из-за чего всё сводится к XPath запросу и пробежки циклом. Все ссылки на страницы расположены в дивах с классом "list"

Так, прежде чем приступить к парсингу проведём пару подготовительных операций. Для начала переменные :
public static WebClient wClient;
//Для указания кодировки страницы
public static Encoding encode = System.Text.Encoding.GetEncoding("utf-8");
Далее прямо в main используем следующий код: wClient = new WebClient();
wClient.Proxy = null;
wClient.Encoding = encode;
var doc = new HtmlDocument();
doc.LoadHtml(wClient.DownloadString("http://dota2.ru/heroes/"));
Далее работаем с нашим документов как с обычной XML. Я использовал XPath запрос для нахождения всех нодов с классом "list"
var listsNode = doc.DocumentNode.SelectNodes("//div[@class='list']");
В теории у нас получается коллекция нодов, все дочерние элементы этих нодов это ноды "a" с атрибутов "href" значения которого ссылка на нужную нам страницу. Переходим к перебору, далее пояснения даются в комментариях к коду.
//перебираем все ноды с классом "list"
foreach (HtmlNode s in listsNode)
{
//перебираем все дочернии ноды нода.
foreach (HtmlNode aNode in s.ChildNodes)
{
//на всякий случай проверяем не подсунули ли на чего-то не того.
if (aNode.Name == "a")
{
//получаем все атрибуты с именнем href (вообще-то он вероятней всего будет 1)
var hrefs = aNode.Attributes.AttributesWithName("href");
foreach (HtmlAttribute hrefAttribute in hrefs)
{
//Выводим ссылку в консольку.
HeroesPages.Add(hrefAttribute.Value);
}
}
}
}
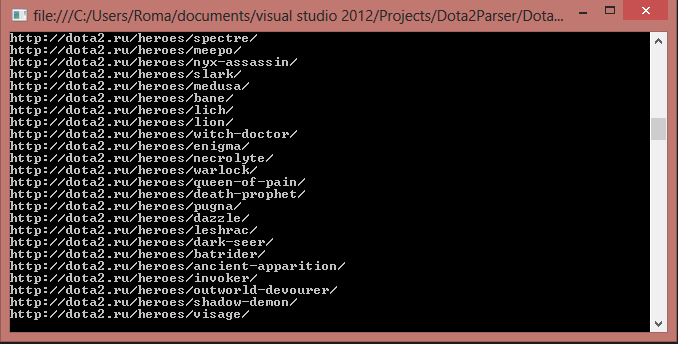
В итоге у нас получится вот что
Комментариев нет:
Отправить комментарий